 Reading Time: 6 minutes
Reading Time: 6 minutes
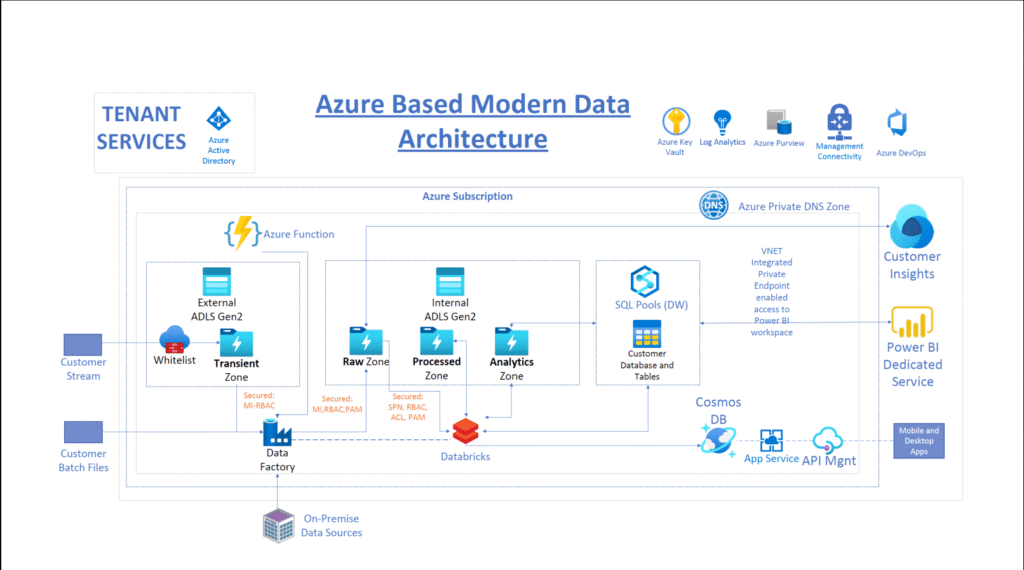
Azure Data Lake Architecture Overview
Data Sources:
- Structured Data: Databases, ERP systems, etc.
- Semi-Structured Data: JSON, XML, etc.
- Unstructured Data: Images, videos, logs, etc.
- Streaming Data: IoT devices, real-time event streams.
Ingestion Layer:
- Azure Data Factory: For batch data ingestion.
- Azure Event Hubs or Azure IoT Hub: For real-time data ingestion.
- Azure Logic Apps: For workflow automation.
Storage Layer:
- Azure Data Lake Storage Gen2: Centralized, scalable storage for raw data.
- Blob Storage: For additional unstructured data storage.
Processing Layer:
- Azure Databricks: For big data processing and machine learning.
- Azure Synapse Analytics: For data transformation and querying.
- Azure Stream Analytics: For real-time data processing.
Analytics & Serving Layer:
- Azure Synapse Analytics: For data warehousing and analytics.
- Azure Analysis Services: For semantic modeling.
- Power BI: For data visualization and reporting.
Governance & Security:
- Azure Active Directory (AAD): For identity and access management.
- Azure Purview: For data cataloging and lineage tracking.
- Role-Based Access Control (RBAC): For secure access.
Monitoring:
- Azure Monitor: For performance and health monitoring.
- Azure Log Analytics: For log data analysis.
- Textual Representation of the Architecture
+——————-+ +——————-+ +——————-+
| Data Sources | —> | Ingestion Layer | —> | Storage Layer |
| (Structured, Semi-| | (Data Factory, | | (Data Lake Gen2, |
| Structured, | | Event Hubs, IoT) | | Blob Storage) |
| Unstructured) | +——————-+ +——————-+
+——————-+
+——————-+ +——————-+ +——————-+
| Processing Layer | —> | Analytics Layer | —> | Visualization & |
| (Databricks, | | (Synapse, | | Reporting (Power |
| Synapse, Stream | | Analysis Services)| | BI, Dashboards) |
| Analytics) | +——————-+ +——————-+
+——————-+
+——————-+ +——————-+
| Governance Layer | | Monitoring Layer |
| (Purview, RBAC, | | (Azure Monitor, |
| AAD) | | Log Analytics) |
+——————-+ +——————-+
This modular architecture ensures scalability, security, and flexibility for handling diverse data types and workloads. You can use tools like Microsoft Visio, Lucidchart, or Draw.io to create a visual diagram based on this structure.

_________________________________________________________________________________
Oracle Autonomous Data Warehouse

Oracle Autonomous Data Warehouse is a cloud-based data and analytics platform designed to simplify and optimize data management and analysis. It is the world’s first and only autonomous database optimized for analytic workloads, including data marts, data warehouses, data lakes, and data lakehouses. This platform allows data scientists, business analysts, and non-experts to rapidly, easily, and cost-effectively discover business insights using data of any size and type.
Key Features
Autonomous Management
Oracle Autonomous Data Warehouse automates many complex tasks such as provisioning, configuring, securing, tuning, and scaling. This eliminates nearly all manual tasks, reducing the risk of human error and enabling customers to run a high-performance, highly available, and secure data warehouse.
Performance and High Availability
The platform continuously monitors all aspects of system performance and autonomously adjusts to ensure consistent high performance, even as workloads, query types, and the number of users vary over time. It provides more than 99.995% availability with built-in Oracle Real Application Clusters, parallel infrastructure, automated disaster recovery, and backups.
Data Lakehouse Foundation
Oracle Autonomous Data Warehouse provides the foundation for a data lakehouse, combining the power and richness of data warehouses with the flexibility and low cost of data lake technologies. This enables easier data movement and a more unified architecture
Self-Service Analytics
The platform empowers business users by reducing their dependency on IT, using self-service data tools, and creating low-code analytic applications. It integrates with Oracle Analytics Cloud, Tableau, and other business intelligence applications to enhance collaboration and business storytelling
Advanced Data Security
Oracle Autonomous Data Warehouse offers advanced data security features, including automated self-patching, always-on encryption, key management, granular access controls, and flexible data masking. These features help reduce the risk of data breaches and simplify regulatory compliance
Machine Learning and AI
The platform includes built-in machine learning and AI capabilities, allowing users to build and deploy machine learning models using scalable and optimized in-database algorithms. It also supports graph analytics and spatial analytics for deeper insights
Benefits
Cost Reduction: According to an IDC report, Oracle Autonomous Data Warehouse lowers operational costs by an average of 63%
Faster Query Performance: The platform is optimized for faster query performance, providing a five-year ROI with a five-month payback period
Reduced DBA Workloads: The automation of complex tasks reduces the workload for database administrators, allowing them to focus on more strategic activities
Oracle Autonomous Data Warehouse is a powerful and efficient solution for modern data management and analytics, offering a wide range of features and benefits to help organizations gain valuable insights from their data.
_________________________________________________________________________________
Amazon Redshift: A Comprehensive Overview

Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud, designed to handle large volumes of data and execute complex analytic queries efficiently. It was introduced in 2013 to address the challenges associated with traditional on-premises data warehousing, such as scalability, cost, and complexity.
Key Features and Benefits
Scalability and Performance: Amazon Redshift can scale from a few hundred gigabytes to several petabytes, allowing businesses to grow their data warehouses as needed. It uses columnar storage and massively parallel processing (MPP) to deliver high-speed query performance.
Integration: Redshift seamlessly integrates with other AWS services like Amazon S3, Amazon RDS, and AWS Glue, creating a comprehensive data ecosystem. This integration allows users to query data across different sources without moving or duplicating data.
Cost-Effectiveness: Amazon Redshift offers a cost-effective solution with various pricing options, enabling users to pay only for the storage and computing power they use. The serverless option further reduces costs by scaling resources automatically based on workload demands.
Security: Redshift provides robust security features, including network isolation, fine-grained access controls, and encryption for data at rest and in transit using AWS Key Management Service (KMS)
How Amazon Redshift Works
Amazon Redshift organizes its resources into clusters, each consisting of one or more compute nodes. A leader node manages client connections and SQL processing, while compute nodes execute queries and store data. The architecture minimizes disk reads and increases performance for analytical queries by organizing data in a columnar format
Query Execution
Redshift runs each query in parallel across multiple nodes, distributing workloads and processing large datasets efficiently. This MPP architecture significantly reduces query processing time
Data Storage
Data in Redshift is stored in a columnar format, which is optimized for read-heavy operations common in data warehousing. This format enhances query performance, especially for complex analytical requests
Use Cases
Business Intelligence: Companies use Redshift to process complex queries, generate reports, and gain insights into their data, supporting decision-making processes
Data Warehousing: Redshift serves as a central data warehouse, storing and analyzing data from various sources
Big Data Analytics: With its petabyte-scale capacity, Redshift enables enterprises to analyze large datasets, identifying trends and patterns
Machine Learning: Redshift supports building, training, and deploying machine learning models using SQL, facilitating advanced analytics on large datasets
Setting Up and Using Amazon Redshift
Step-by-Step Process
Create a Redshift Cluster: Sign in to the AWS Management Console, navigate to Redshift, and create a cluster by configuring the necessary settings
Configure Security and Access: Create and attach an IAM role to grant Redshift permissions to access other AWS services
Create Tables: Define your table schema using the CREATE TABLE statement
Load Data: Use the COPY command to load data from sources like Amazon S3 into Redshift
Example of Creating a Table and Loading Data
CREATE TABLE sales (
sales_id INT,
product_name VARCHAR(255),
quantity INT,
price DECIMAL(10, 2),
sale_date DATE
);
COPY sales
FROM ‘s3://your-bucket/your-data’
IAM_ROLE ‘arn:aws:iam::your-account-id:role/your-iam-role’
FORMAT AS CSV;
Amazon Redshift is a powerful, scalable, and cost-effective data warehousing solution that enables businesses to analyze large volumes of data quickly and efficiently. Its integration with other AWS services, robust security features, and support for advanced analytics make it an ideal choice for organizations looking to leverage their data for insights and decision-making
Best Data Warehouse Tools
1. Amazon Redshift
2. Microsoft Azure
3. Google BigQuery
4. Snowflake
5. Postgres SQL
6. Amazon S3
7. Teradata
8. Oracle Autonomous Warehouse