 Reading Time: 4 minutes
Reading Time: 4 minutes
Status: Final Blueprint
Author: Shahab Al Yamin Chawdhury
Organization: Principal Architect & Consultant Group
Research Date: October 26, 2023
Location: Dhaka, Bangladesh
Version: 1.0
Executive Summary
The Data Lakehouse paradigm marks a critical evolution in enterprise data architecture, merging the strengths of traditional Data Warehouses and Data Lakes. It creates a unified platform for diverse analytical workloads, from BI to AI/ML, enhancing data accessibility, quality, governance, performance, and cost efficiency. This blueprint outlines its architecture, impact, use cases, implementation, and future, serving as a strategic guide for architects and consultants.
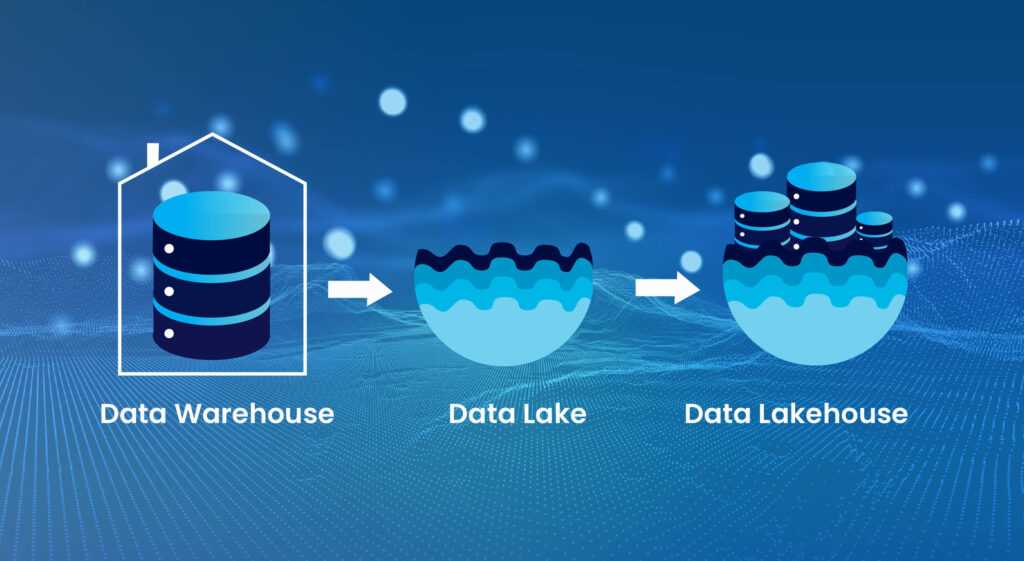
1. The Evolving Landscape of Enterprise Data Architectures
Historically, Data Warehouses (DWs) offered high data quality and governance for structured BI, but lacked flexibility and scalability for diverse, large datasets. Data Lakes (DLs) emerged for cost-effective storage of raw, multi-structured data, supporting exploratory analytics and ML, but often suffered from poor data quality and governance (“data swamps”).
The Data Lakehouse (DLH) represents a convergence, combining DW reliability (ACID transactions, schema enforcement) with DL flexibility and scalability. It eliminates data silos, providing a unified source of truth for all analytical needs, and addresses the “data swamp” problem by bringing trustworthiness to the lake environment. Its foundation rests on open data formats (Parquet, ORC) and decoupled compute/storage, fostering flexibility and avoiding vendor lock-in.
Comparative Snapshot:
- DW: Structured, schema-on-write, high quality, ACID, limited scale, high cost, for BI.
- DL: Raw/multi-structured, schema-on-read, low/variable quality, no ACID, high scale, low cost, for Data Science/ML.
- DLH: Multi-structured, hybrid schema, high quality, ACID, high scale, optimized cost, for unified BI, Data Science, ML, AI, Real-time.
2. Deep Dive into Data Lakehouse Architecture and Technologies
The DLH comprises three decoupled layers:
- Storage Layer: Cloud object storage (AWS S3, Azure ADLS, GCS) for massive, cost-effective storage of data in open, columnar formats (Parquet, ORC).
- Metadata/Transactional Layer: The core differentiator, providing DW-like capabilities (ACID transactions, schema evolution, time travel, upserts/deletes) directly on object storage. Key technologies include Delta Lake, Apache Iceberg, and Apache Hudi. This layer transforms raw lake data into reliable, governed assets.
- Compute Layer: Decoupled from storage, allowing independent scaling. Includes engines like Apache Spark (ETL, ML), Presto/Trino (interactive SQL), and Apache Flink (streaming).
Leading platforms like Databricks Lakehouse Platform (native Delta Lake), Snowflake (embracing Iceberg), and composite solutions from AWS, Azure, and Google Cloud offer various managed services built on these principles.
3. The Transformative Impact of Data Lakehouse on Analytics
The DLH profoundly impacts analytics by:
- Unifying Workloads: Consolidating BI, ML, and AI on a single platform, eliminating data silos, reducing ETL complexity, and accelerating time-to-insight for data-driven products.
- Enhancing Data Quality & Governance: Transactional layers enforce schema, provide ACID properties, and enable data versioning/time travel, ensuring reliability and compliance. Granular access controls bolster security.
- Achieving Superior Performance & Cost Efficiency: Decoupled compute/storage allows independent scaling and optimized resource utilization. Open formats and indexing further boost query performance.
- Enabling Real-time Analytics: Supports real-time ingestion and processing for operational analytics, fraud detection, and personalized experiences, shifting decision-making from reactive to predictive.
4. Strategic Use Cases and Industry-Specific Applications
The DLH drives innovation across sectors:
- Financial Services: Real-time fraud detection, comprehensive risk management.
- Healthcare: Personalized patient care, operational efficiency (e.g., patient flow).
- Retail & E-commerce: Customer 360, hyper-personalization, supply chain optimization.
- Manufacturing: Predictive maintenance, enhanced quality control.
Quantifiable benefits include significant cost reduction, accelerated time-to-insight, improved data quality, enhanced business agility, and increased revenue opportunities through new data-driven products and operational excellence.
5. Implementation Strategies, Best Practices, and Migration Paths
A phased, agile approach is recommended for DLH adoption:
- Assessment: Analyze current state, gather business requirements, evaluate tech stack.
- Design & PoC: Create architectural blueprint, data models, security design; validate with a Proof of Concept.
- Migration: Implement data ingestion (batch, streaming, CDC), transform data into a medallion architecture (Bronze, Silver, Gold layers), and migrate existing workloads.
- Optimization: Continuous performance tuning, cost management, and feature expansion.
Adopting a “data product” mindset, where curated datasets are treated as products with clear ownership and documentation, is crucial for success.
6. Challenges, Risks, and Mitigation Strategies
Common challenges include:
- Complexity: Mitigate with PoCs, managed services, robust design, and documentation.
- Skill Gaps: Address through training, hiring specialized talent, or engaging consultants.
- Data Governance Hurdles: Establish clear ownership, automated quality checks, and comprehensive metadata management.
Hidden costs of DIY Lakehouse implementations often favor leveraging expert consultants or managed platforms for faster time-to-value and risk mitigation. Data literacy programs are also vital to ensure users can effectively leverage the platform.
7. Future Trends and the Evolution of Data Lakehouse
The DLH is an evolving architecture, integrating with broader data strategies:
- Enhanced Interoperability: Continued advancements in open table formats.
- Streaming-First Architectures: Becoming the foundation for real-time data processing.
- Data Mesh & Data Fabric Integration: Provides a technical foundation for decentralized data ownership and unified data access.
- Semantic Layer Evolution: Simplifying data consumption for business users.
- AI/ML in Advancing Functionalities: AI/ML will automate data management (schema inference, quality monitoring), enable self-optimizing Lakehouses, and enhance data discovery/governance, leading to “intelligent data platforms.”
The Data Lakehouse is positioned as a “future-proof” investment, enabling organizations to adapt to evolving business and technological demands.
Conclusion
The Data Lakehouse architecture is a fundamental shift, unifying BI, ML, and AI on a single, governed, and scalable platform. It delivers superior performance, cost efficiency, and enables real-time analytics and advanced data applications. For principal architects and consultants, embracing the Lakehouse as a strategic imperative, prioritizing open standards, adopting agile implementation, investing in governance and literacy, and focusing on business value are critical recommendations for charting a data-driven future.